Blogs / I Ditched Schemas For PostgreSQL’s JSONB In Our Document Parser - Here’s Why
I Ditched Schemas For PostgreSQL’s JSONB In Our Document Parser - Here’s Why
August 1, 2024 • Matthew Duong • Software Engineering • 6 min read

About the project
In my day job, one of the most interesting projects I’ve worked on is the document parsing and extraction engine, informally known as the “document center.” This engine processes various types of scanned or photographed documents commonly encountered by accountants, such as receipts, contracts, invoices, and bills. To automate repetitive bookkeeping tasks, the system initiates workflows upon document ingestion, like matching invoices with bank transactions, updating the general ledger, and creating accrued expense entries. While there are multiple workflows triggered by different document types, this article will focus on why I chose to ditch schemas in favor of PostgreSQL’s JSONB for storing dynamic data in our document parser.
How we process documents
Here’s a high-level overview of the system workflow:
- An accountant forwards the document to our ingestion inbox.
- We ingest the document and use OCR to extract all the text.
- The text is classified into specific categories such as receipt, invoice, bill, contract, or unknown.
- Based on the document type, a parser job extracts specific fields (e.g., the last four digits of a credit card on a receipt).
- The extracted fields are stored in our database.
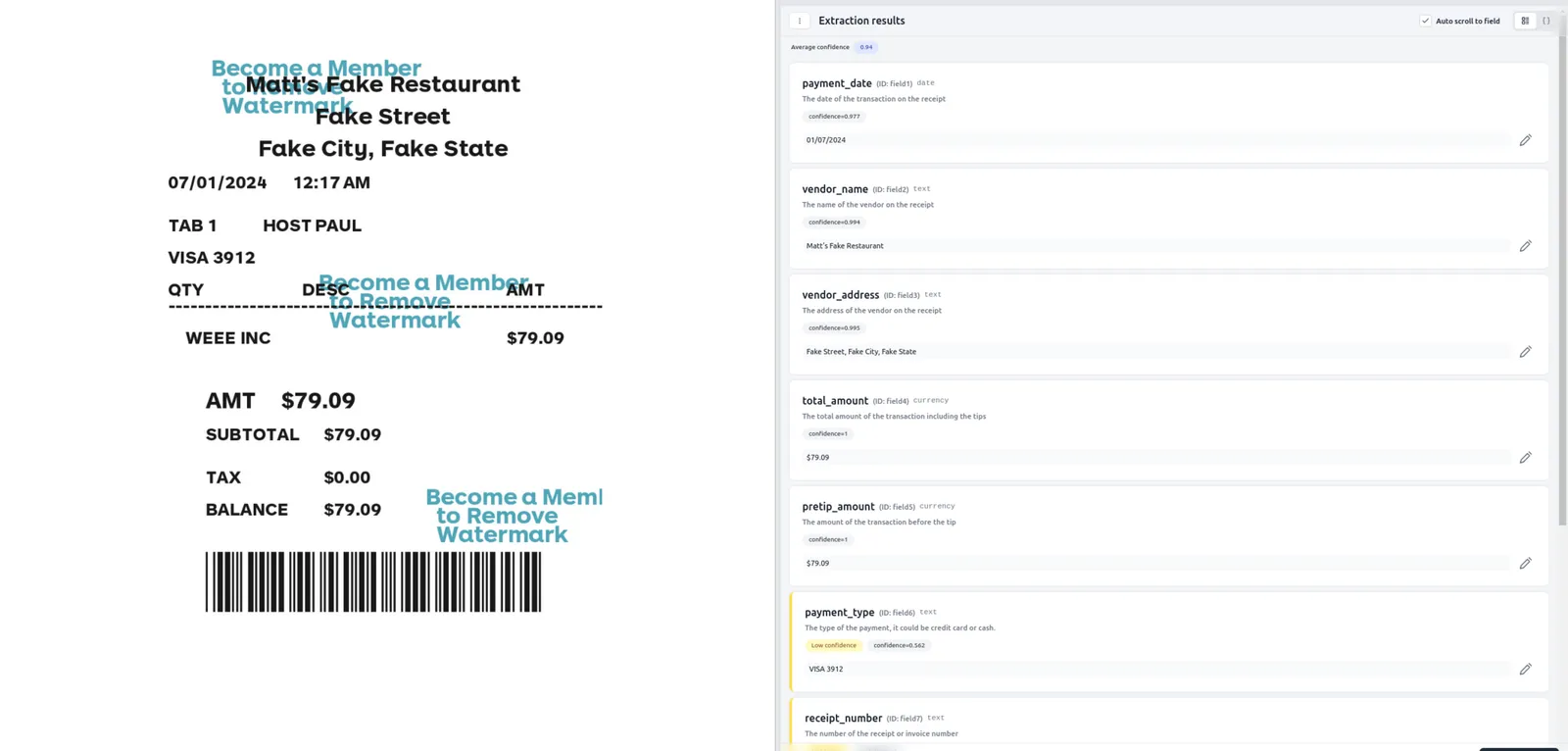
Where is the complexity?
At first glance, creating a database schema for the extracted fields seems straightforward. However, this approach quickly becomes impractical as we ingest a wider variety of documents. New document types often require additional fields that were not part of the original schema, necessitating frequent updates. This constant evolution makes the schema akin to a living organism.
The challenge is further compounded by the need to maintain backward compatibility and data integrity across different versions of our parser and extraction jobs. Each new version might introduce changes to the schema, necessitating complex database migrations. From a dev experience perspective, migrations are always a pain to deal with. These migrations are also particularly challenging when dealing with any sizable volumes in production data.
For example, an initial schema for a receipt might include fields like date, total_amount, and merchant. However, as new types of receipts are processed, additional fields such as tax_amount, discount, and payment_method might be required. Manually updating the schema for each new field introduces significant overhead and risks disrupting existing workflows.
To address these complexities, I opted for a schemaless approach using PostgreSQL’s JSONB. This strategy allows me to dynamically adapt to new fields and versions without extensive manual intervention or disruption to existing data flows.
Challenges with data consistency
Data consistency is the primary concern with this approach. Without strict schema constraints, the database can store data outside the intended schema. This flexibility, while beneficial for rapid development and accommodating diverse document types, introduces risks. Potential sources of data contamination include:
- Bugs in Code: Errors in the parsing or extraction logic can result in malformed or incorrect data being stored. For example, a bug might misclassify a field or fail to extract all necessary information, leading to incomplete records.
- Schema Drift: Over time, as different versions of the extraction jobs evolve, the fields and structure of the JSON data can drift, making it challenging to maintain a consistent data model. Without strict constraints, older records may not conform to the newer schema, complicating data retrieval and analysis.
- Inconsistent Data Types: In a schemaless design, fields may store varying data types across different records. For instance, a field intended to store numerical values might sometimes contain strings.
My solution
Fortunately I have spent some time working on this exact problem. In many of my side projects, I opt for a NOSQL database, which for the most part is schemaless. For me, the tried and tested method is to use schema versioning. Simply put, it is a solution that involves storing schema versions as part of the payload. Each version of the extraction job is accompanied by a corresponding schema embedded in the application code. This job version is included within the JSON data.

Example
Here is a very basic example to illustrate the concept.
Raw payload
This is an example of what is stored in the JSONB field.
{
"version": "1.0",
"date": "2023-07-01",
"total_amount": 25.50,
"merchant": "Store A"
}
Typescript Interface
The application schema that represents the above versioned payload.
interface ReceiptV1 {
readonly version: "1.0";
readonly date: string;
readonly total_amount: number;
readonly merchant: string;
}
Runtime Validation Schema
This is the corresponding runtime schema used to serialize and validate the payload when it is fetched.
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "ReceiptV1",
"type": "object",
"properties": {
"version": {
"type": "string",
"const": "1.0"
},
"date": {
"type": "string",
"format": "date"
},
"total_amount": {
"type": "number"
},
"merchant": {
"type": "string"
}
},
"required": ["version", "date", "total_amount", "merchant"],
"additionalProperties": false
}
A potential downside is maintaining synchronization with the TypeScript interface, which can be cumbersome. In a previous project, I addressed this by creating a code generation library that converts TypeScript interfaces into JSON Schema, as demonstrated above. You can find this library here: https://www.npmjs.com/package/ts-runtime-validation
Technical Details
Schema Embedding: Each extraction job includes its schema definition within the application code, ensuring that every job version has an associated schema for reference during data processing.
Versioning Field: Each JSON document includes a version identifier, indicating the schema version used for extraction. This allows the system to identify and apply the correct schema during data operations.
Efficient Serialization: The version property enables efficient serialization and deserialization of JSON data. The system uses the version identifier at runtime to ensure accurate and consistent data processing.
Strict Typing and Discriminated Unions: Utilizing a strictly typed language or framework like TypeScript or Scala, we enforce runtime checks on the payload. Discriminated unions help differentiate between schema versions, ensuring data conforms to the expected structure.
Backward Compatibility: This method supports backward compatibility, allowing older data with previous schema versions to be read and processed correctly using the version identifier.
TL;DR
At Truewind, I used PostgreSQL’s JSONB for dynamic data storage in our document parser. This schemaless approach allows flexibility for a broad range of documents without manual schema updates. Key challenges include maintaining data consistency and handling schema drift. I address these by embedding schema versions in the JSON data, ensuring integrity and backward compatibility.